

.
As cenas da área de Houston pareciam o rescaldo de um furacão no início de maio de 2024, depois que uma série de fortes tempestades inundaram rodovias e bairros e enviaram rios para suas margens ao norte da cidade.
Centenas de pessoas tiveram que ser resgatadas de casas, telhados e carros durante tempestades, segundo a Associated Press. Huntsville registrou quase 50 centímetros de chuva de 29 de abril a 4 de maio. Outro sistema de tempestade em meados de maio estourou janelas em arranha-céus de Houston e causou mais inundações repentinas nas ruas urbanas e no solo já saturado da região.
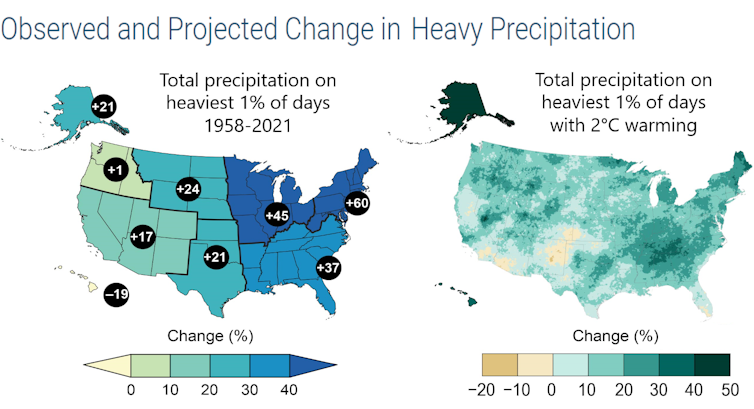
As inundações são eventos complexos e envolvem mais do que apenas chuvas fortes. Cada comunidade tem a sua geografia e clima únicos que podem agravar as inundações. Além destes riscos, as chuvas extremas estão a tornar-se mais comuns à medida que as temperaturas globais aumentam.




Trabalho num centro da Universidade de Michigan que ajuda as comunidades a transformar o conhecimento climático em projetos que podem reduzir os danos de futuros desastres climáticos. Eventos de inundação como os ocorridos na área de Houston fornecem estudos de caso que podem ajudar cidades em todos os lugares a gerenciar o risco crescente.

Chengyue Lao/Xinhua via Getty Images
Os riscos de inundação estão aumentando
A primeira coisa que as recentes inundações nos dizem é que o clima está a mudar.
No passado, poderia ter feito sentido considerar uma inundação um evento raro e aleatório – as comunidades poderiam simplesmente reconstruir. Mas a distribuição estatística dos fenómenos meteorológicos e dos desastres naturais está a mudar.
O que poderia ter sido um evento que ocorre 1 em 500 anos pode se tornar um evento que ocorre em 100 anos, a caminho de se tornar um evento em 50 anos. Quando o furacão Harvey atingiu o Texas em 2017, causou a terceira inundação de 500 anos em Houston no período de três anos.
A física básica aponta para os riscos crescentes: As emissões globais de gases com efeito de estufa estão a aumentar as temperaturas médias globais. O aquecimento leva ao aumento da precipitação e a chuvas mais intensas, bem como ao aumento do potencial de inundações, especialmente quando as tempestades atingem solos já saturados.
As comunidades não estão preparadas
As recentes inundações também revelam vulnerabilidades na forma como as comunidades são concebidas e geridas.
O pavimento é um dos principais contribuintes para as inundações urbanas, porque a água não pode ser absorvida e escoa rapidamente. As frequentes inundações na área de Houston ilustram os riscos. As suas superfícies impermeáveis expandiram-se em 386 milhas quadradas (1.000 quilómetros quadrados) entre 1997 e 2017, de acordo com dados recolhidos pela Rice University. Mais ruas, estacionamentos e edifícios significavam mais água parada e menos locais para a água da chuva penetrar.
Se a infra-estrutura for bem concebida e mantida, os danos causados pelas inundações podem ser grandemente reduzidos. No entanto, cada vez mais, os investigadores têm descoberto que as especificações de engenharia para tubos de drenagem e outras infra-estruturas já não são adequadas para lidar com a crescente severidade das tempestades e da quantidade de precipitação. Isto pode levar à destruição de estradas e ao isolamento de comunidades. Falhas na manutenção de infra-estruturas, tais como diques e galerias de águas pluviais, são um contribuinte comum para as inundações.
Na área de Houston, os reservatórios também são uma parte essencial da gestão das cheias, e muitos estavam esgotados devido às chuvas persistentes. Isso forçou os gestores a liberar mais água quando as tempestades começaram.
Para uma metrópole costeira como a área de Houston-Galveston, o rápido aumento do nível do mar também pode reduzir a capacidade a jusante de gerir a água. Estes diferentes factores aumentam o risco de inundações e realçam a necessidade não só de movimentar a água, mas também de encontrar locais seguros para a armazenar.
Avaliação Climática Nacional 2023
Os riscos crescentes afectam não só as normas de engenharia, mas também as leis de zoneamento que regem os locais onde as casas podem ser construídas e os códigos de construção que descrevem as normas mínimas de segurança, bem como as regulamentações ambientais e de licenciamento.
Ao abordar estas questões agora, as comunidades podem antecipar e evitar danos, em vez de reagirem apenas quando for tarde demais.
Quatro lições de estudos de caso
Os muitos efeitos associados às inundações mostram por que é necessária uma abordagem holística ao planeamento das alterações climáticas e o que as comunidades podem aprender umas com as outras. Por exemplo, estudos de caso mostram que:

Imagens de Scott Olson/Getty
-
É difícil para um indivíduo ou uma comunidade assumir sozinho até mesmo os aspectos técnicos da preparação para cheias – há demasiada interligação. Medidas de protecção como diques ou canais podem proteger um bairro, mas agravam o risco de inundações a jusante. Os planeadores devem identificar a escala regional apropriada, tal como toda a bacia de drenagem de um riacho ou rio, e estabelecer relações importantes no início do processo de planeamento.
-
Os desastres naturais e a forma como as comunidades lhes respondem também podem amplificar as disparidades em termos de riqueza e recursos. A justiça social e as considerações éticas precisam ser incluídas no planejamento desde o início.
Aprendendo a gerenciar a complexidade
Nas comunidades com as quais os meus colegas e eu trabalhámos, encontrámos uma consciência cada vez maior dos desafios das alterações climáticas e dos riscos crescentes de inundações.
Na maioria dos casos, o instinto inicial das autoridades locais tem sido o de proteger a propriedade e persistir sem alterar o local onde as pessoas vivem. No entanto, isso só poderá ganhar tempo para algumas áreas, antes que as pessoas não tenham outra opção senão mudar-se.
Ao examinarem as suas vulnerabilidades, muitas destas comunidades começaram a reconhecer a interligação entre o zoneamento, as galerias pluviais e os parques que podem absorver o escoamento, por exemplo. Começam também a perceber a importância de envolver as partes interessadas regionais para evitar esforços fragmentados de adaptação que poderiam piorar as condições das zonas vizinhas.
Esta é uma versão atualizada de um artigo publicado originalmente em 25 de agosto de 2022.
.



