

.
O clima da Terra está mudando rapidamente. Em algumas áreas, as temperaturas crescentes estão aumentando a frequência e a probabilidade de incêndios florestais e secas. Em outros, eles estão tornando as chuvas e tempestades mais intensas ou acelerando o ritmo do derretimento glacial.
O mês passado é uma ilustração gritante exatamente disso. Partes da Europa e do Canadá estão sendo devastadas por incêndios florestais, enquanto Pequim registrou as chuvas mais fortes em pelo menos 140 anos. Olhando para trás, entre 2000 e 2019, as geleiras do mundo perderam cerca de 267 gigatoneladas de gelo por ano. O derretimento das geleiras contribui para o aumento do nível do mar (atualmente subindo cerca de 3,3 mm por ano) e mais riscos costeiros, como inundações e erosão.
Mas a pesquisa sugere que nosso clima em mudança pode não apenas influenciar os perigos na superfície da Terra. As mudanças climáticas – e especificamente o aumento das taxas de chuva e o derretimento glacial – também podem exacerbar os perigos abaixo da superfície da Terra, como terremotos e erupções vulcânicas.




A seca na Europa e na América do Norte recebeu muita cobertura da mídia recentemente. Mas o Sexto Relatório de Avaliação do Painel Intergovernamental sobre Mudanças Climáticas em 2021 revelou que a precipitação média na verdade aumentou em muitas regiões do mundo desde 1950. Uma atmosfera mais quente pode reter mais vapor de água, levando subsequentemente a níveis mais altos de precipitação.
Curiosamente, os geólogos há muito identificam uma relação entre as taxas de chuva e a atividade sísmica. No Himalaia, por exemplo, a frequência dos terremotos é influenciada pelo ciclo anual de chuvas da estação das monções de verão. A pesquisa revela que 48% dos terremotos do Himalaia ocorrem durante os meses mais secos pré-monções de março, abril e maio, enquanto apenas 16% ocorrem na estação das monções.
Durante a estação das monções de verão, o peso de até 4 metros de chuva comprime a crosta vertical e horizontalmente, estabilizando-a. Quando esta água desaparece no inverno, o efetivo “rebote” desestabiliza a região e aumenta o número de terremotos que ocorrem.
O número de terremotos que ocorreram sazonalmente de 2003 a 2020
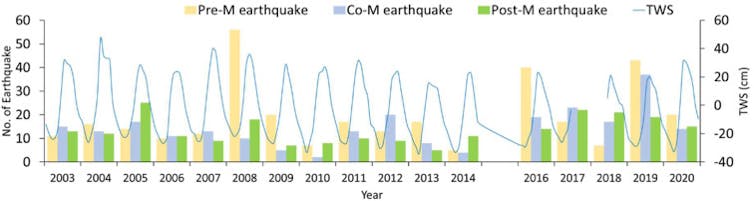
Shashikant Nagale et ai. (2022)/Geodesia e Geodinâmica, CC BY-NC-ND
As mudanças climáticas podem intensificar esse fenômeno. Os modelos climáticos projetam que a intensidade das chuvas de monção no sul da Ásia aumentará no futuro como resultado das mudanças climáticas. Isso poderia aumentar a recuperação do inverno e causar mais eventos sísmicos.
O impacto do peso da água na crosta terrestre vai além da simples precipitação; estende-se ao gelo glacial também. Quando a última era do gelo chegou ao fim, há cerca de 10.000 anos, o degelo de pesadas massas de gelo glacial fez com que partes da crosta terrestre se recuperassem. Esse processo, chamado rebote isostático, é evidenciado por praias elevadas na Escócia – algumas das quais chegam a 45 metros acima do nível do mar atual.
Evidências da Escandinávia sugerem que tal elevação, juntamente com a desestabilização da tectônica da região, desencadeou vários terremotos entre 11.000 e 7.000 anos atrás. Alguns desses terremotos excederam a magnitude de 8,0, o que indica destruição severa e perda de vidas. A preocupação é que o derretimento contínuo do gelo glacial hoje possa resultar em efeitos semelhantes em outros lugares.

Patrick Bailey/Royal Scottish Geographical Society, CC BY-NC-ND
E a atividade vulcânica?
A pesquisa também encontrou uma correlação entre as mudanças de carga glacial na crosta terrestre e a ocorrência de atividade vulcânica. Aproximadamente 5.500–4.500 anos atrás, o clima da Terra esfriou brevemente e as geleiras começaram a se expandir na Islândia. A análise dos depósitos de cinzas vulcânicas espalhados por toda a Europa sugere que a atividade vulcânica na Islândia reduziu acentuadamente durante esse período.
Houve um aumento subseqüente na atividade vulcânica após o fim deste período frio, embora com um atraso de várias centenas de anos.
Esse fenômeno pode ser explicado pelo peso das geleiras comprimindo tanto a crosta terrestre quanto o manto subjacente (a maior parte do volume sólido do interior da Terra). Isso manteve o material que compõe o manto sob maior pressão, impedindo-o de derreter e formar o magma necessário para as erupções vulcânicas.
No entanto, a deglaciação e a perda de peso associada na superfície da Terra permitiram que ocorresse um processo chamado fusão por descompressão, onde a pressão mais baixa facilita a fusão no manto. Esse derretimento resultou na formação do magma líquido que alimentou a atividade vulcânica subsequente na Islândia.
Ainda hoje, esse processo é responsável por impulsionar algumas atividades vulcânicas na Islândia. Erupções em dois vulcões, Grímsvötn e Katla, ocorrem consistentemente durante o período de verão, quando as geleiras recuam.
Portanto, é possível que o recuo glacial em curso devido ao aquecimento global possa aumentar a atividade vulcânica no futuro. No entanto, o intervalo de tempo entre as mudanças glaciais e a resposta vulcânica é reconfortante por enquanto.

muratart/Shutterstock
Os impactos de um clima em mudança estão se tornando mais evidentes, com eventos climáticos incomuns se tornando a norma e não a exceção. No entanto, os impactos indiretos das mudanças climáticas no solo sob nossos pés não são amplamente conhecidos ou discutidos.
Isso deve mudar se quisermos minimizar os efeitos da mudança climática que já foram colocados em ação.

Não tem tempo para ler sobre mudanças climáticas tanto quanto gostaria?
Receba um resumo semanal em sua caixa de entrada. Toda quarta-feira, o editor de meio ambiente do Strong The One escreve Imagine, um e-mail curto que se aprofunda um pouco mais em apenas uma questão climática. Junte-se aos mais de 20.000 leitores que se inscreveram até agora.
.



