

A arquitetura orientada a eventos é um paradigma que permite baixo acoplamento entre serviços, principalmente em uma arquitetura de microsserviços. Ele elimina a necessidade de os serviços se conhecerem ativamente e consultarem uns aos outros usando APIs síncronas. Isso nos permite reduzir a latência (evitando o “inferno dos microsserviços”) e facilitar a mudança de serviços isoladamente.
Em poucas palavras, essa abordagem usa um agente de mensagens que gerencia vários tópicos (também conhecidos como logs ou fluxos ). Um serviço produz para um tópico, enquanto outros serviços consomem do tópico.
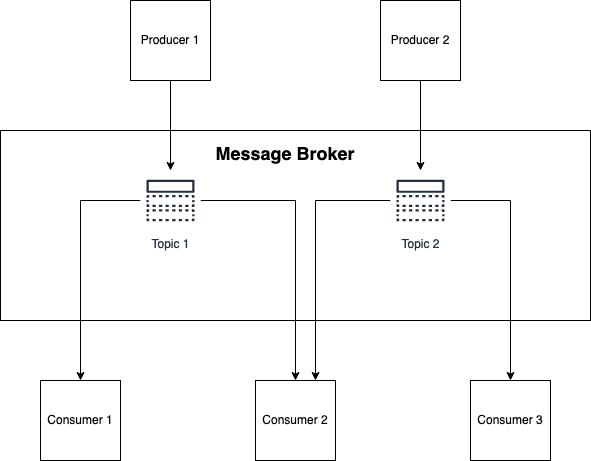
Cada uma dessas pequenas caixas pretas provavelmente desejará ter seu próprio estado para realizar seu trabalho. (Serviços sem estado existem, mas para que algo seja realmente sem estado, há uma série de compensações e pontos problemáticos que você precisa resolver e geralmente refletem uma arquitetura de microsserviço mais complexa. Na maioria das vezes, essas arquiteturas podem ser descritas como um “ distribuiu uma grande bola de lama .”)
Nosso objetivo ao introduzir um agente de mensagens é reduzir as dependências entre essas caixas. Isso significa que, se o serviço A tiver alguma informação, o serviço B não deve pedir ao serviço A essas informações diretamente – o serviço A publicará essas informações em um tópico. O serviço B pode então consumir as informações e salvá-las em seu próprio armazenamento de dados ou fazer algum trabalho com elas.




Ignorando os desafios mais técnicos dessa abordagem no lado da produção ou do consumo (como casar a produção de mensagens com as transações do banco de dados), que tipo de dados é útil enviar por meio de tópicos? Como podemos mover com facilidade e segurança nossos dados armazenados de um serviço para outro? E como são nossos tópicos e serviços em diferentes situações?
Vamos começar a responder a essas perguntas.
kafkiano
Para os propósitos desta discussão, usarei o Apache Kafka como a tecnologia subjacente ao agente de mensagens em questão. Além das vantagens em coisas como sua capacidade de dimensionar, recuperar e processar coisas rapidamente, o Kafka possui algumas propriedades que tornam seus tópicos mais úteis do que uma fila simples padrão ou um barramento de mensagens:
- As mensagens têm chaves associadas a elas. Essas chaves podem ser usadas em estratégias de compactação (que exclui todas as mensagens com a mesma chave, exceto a mais recente). Isso é útil em tópicos upsert , que discutirei mais abaixo.
- As mensagens são excluídas apenas pelas configurações de compactação ou retenção (por exemplo, exclua qualquer mensagem com mais de sete dias) — elas não são excluídas manualmente ou assim que são vistas.
- Qualquer número de consumidores (ou melhor, grupos de consumidores) pode ler o mesmo tópico e cada um deles gerencia seus próprios deslocamentos.
O resultado dessas propriedades é que as mensagens permanecem permanentemente no tópico — ou até que sejam limpas por retenção ou compactação — e agem como um registro da verdade.
Kafka também permite estruturar seus dados. Você pode enviar qualquer tipo de dados de byte por meio do Kafka, mas é altamente recomendável usar uma estrutura de esquema como Avro ou Protobuf . Vou um passo além e recomendo que todas as mensagens em um tópico devem usar o mesmo esquema . Existem inúmeros benefícios para isso, mas isso é assunto para outro artigo.
Com essas propriedades e dados fortemente estruturados, podemos projetar tópicos para cada uma das seguintes situações:
- Tópicos de entidade – “este é o estado atual do X”
- Tópicos do evento – “X aconteceu”
- Tópicos de solicitação e resposta” – “Por favor, faça X” → “X foi feito”
Tópicos de entidade: A fonte da verdade
Um tópico de entidade é uma das maneiras mais úteis de usar o Kafka para transportar dados entre serviços. Os tópicos de entidade relatam o estado atual de um objeto .
Como exemplo, digamos que você tenha um Customersserviço que saiba tudo sobre todos os clientes com os quais sua empresa trabalha. Em um mundo síncrono, você faria com que esse serviço configurasse uma API para que todos os outros serviços que precisam saber sobre um cliente tivessem que consultá-lo. Usando o Kafka, você faz com que esse serviço publique em um Customers tópico , do qual todos os outros serviços consomem.
Os serviços ao consumidor podem despejar esses dados diretamente em seu próprio banco de dados. O legal desse paradigma é que cada serviço pode armazenar os dados como quiser. Eles podem descartar campos ou colunas com os quais não se importam ou mapeá-los para diferentes estruturas de dados ou representações. Mais importante ainda, cada serviço possui seus próprios dados . Se o seu Ordersserviço precisa saber sobre os clientes, ele não precisa pedir por isso – ele já o tem em seu próprio banco de dados.

Uma das propriedades do Kafka – o fato de cada mensagem ter uma chave correspondente – é muito eficaz para viabilizar esse tipo de tópico. Você define a chave para qualquer identificador que você precisa para esse cliente – um ID de algum tipo. Então você pode confiar no Kafka para garantir que, eventualmente, você verá apenas um único registro para o cliente com esse ID: a versão mais atualizada do cliente.
Outra propriedade — particionamento — garante que a ordem seja garantida para qualquer mensagem com a mesma chave. Isso significa que você nunca pode consumir mensagens fora de ordem, portanto, sempre que vir esse cliente, saberá com certeza que é a versão mais recente desse cliente que você já viu.
Os consumidores podem inserir o cliente no banco de dados — insira-o se não existir, atualize-o se existir. Kafka ainda tem uma convenção para significar exclusões: uma mensagem com uma chave, mas uma carga nula, também conhecida como tombstone . Isso indica que o registro deve ser excluído. Devido à compactação, todas as mensagens não-tombstone eventualmente desaparecerão, deixando nada além do registro de exclusão (e que também pode ser compactado automaticamente).
Como os tópicos de entidade representam uma exibição externa no estado de propriedade de um serviço existente, você pode exportar o mínimo de informações que precisar. Você sempre pode aprimorar essas informações posteriormente adicionando campos aos dados exportados e republicando-os. (Excluir campos é mais difícil, pois você teria que acompanhar todos os consumidores dos dados para ver se eles estão realmente usando esses campos.)
Os tópicos de entidade são ótimos, mas vêm com uma grande ressalva: eles fornecem consistência eventual . Como os tópicos são assíncronos, nunca é garantido que o que você tem em seu banco de dados corresponda exatamente ao banco de dados do produtor – pode estar segundos ou mesmo minutos desatualizado se seu corretor estiver com lentidão. Se você:
- precisa que seus dados sejam cem por cento precisos no momento do uso, ou
- você precisa reunir informações de mais de uma fonte e ambas as fontes têm links que devem corresponder perfeitamente,
então, usar o processamento assíncrono provavelmente não é o que você deseja: você precisa confiar nas boas e antigas consultas de API.
Tópicos do evento: Registro do fato
Os tópicos de eventos são uma fera completamente diferente dos tópicos de entidade. Os tópicos do evento indicam que uma coisa específica aconteceu. Em vez de fornecer a versão mais atualizada de um dado específico, os tópicos do evento fornecem um registro “burro” das coisas que aconteceram com ele.
(Observe que não vou abordar a origem de eventos , que usa eventos para reconstruir o estado de um registro. Acho que esse padrão é de uso de nicho em contextos específicos e nunca o usei em produção.)
Os eventos são usados principalmente por dois motivos:
- Colete informações sobre o comportamento do usuário ou do aplicativo. Isso geralmente potencializa a análise e a tomada de decisão manual ou automatizada.
- Dispara alguma tarefa ou função quando ocorre um evento específico. Esta é a base de uma arquitetura coreográfica – um design descentralizado onde cada sistema conhece apenas suas próprias entradas.
Ao contrário dos tópicos de entidade, os tópicos de evento só podem capturar o que acontece no momento exato em que acontece. Você não pode adicionar informações arbitrariamente a ele porque essas informações podem ter sido alteradas. Por exemplo, se você quiser adicionar posteriormente o endereço de um cliente a um evento de pedido, precisará cruzar a referência do endereço no momento em que o evento aconteceu , o que geralmente é muito mais trabalhoso do que vale a pena.
Para reafirmar isso, os tópicos de entidade devem ter o mínimo de campos possível , pois é relativamente fácil adicioná-los e difícil excluí-los. Por outro lado, os tópicos do evento devem ter quantos campos você julgar necessários , pois não é possível anexar informações após o fato.
Os tópicos de evento não precisam de chaves de mensagem porque não representam uma atualização para o mesmo objeto. No entanto, eles devem ser particionados corretamente, porque você provavelmente desejará trabalhar em eventos que aconteceram no mesmo registro em ordem.
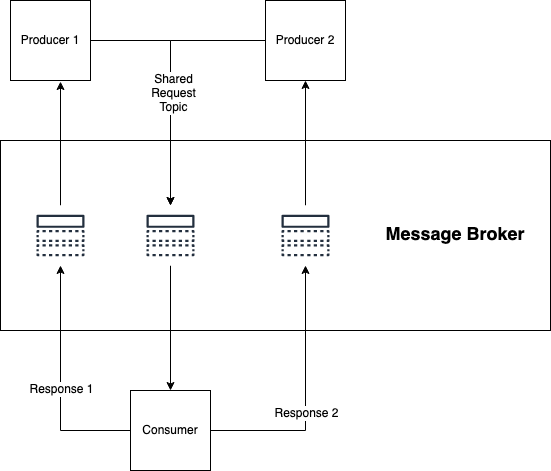
Tópicos de solicitação e resposta: API assíncrona
Os tópicos de solicitação e resposta são mais ou menos o que parecem:
- Um cliente envia uma mensagem de solicitação por meio de um tópico para um consumidor;
- O consumidor executa alguma ação e, em seguida, retorna uma mensagem de resposta por meio de um tópico de volta ao consumidor.
Esse padrão geralmente é um pouco menos útil do que os dois anteriores. Em geral, esse padrão cria uma arquitetura de orquestração , na qual um serviço informa explicitamente a outros serviços o que fazer. Existem alguns motivos pelos quais você pode querer usar tópicos para potencializar isso em vez de APIs síncronas:
- Você deseja manter o baixo acoplamento entre os serviços que um agente de mensagens nos fornece. Se o serviço que está fazendo o trabalho mudar, o serviço de produção não precisa saber disso, pois está apenas disparando uma solicitação em um tópico em vez de perguntar diretamente a um serviço.
- A tarefa leva muito tempo para ser concluída, a ponto de uma solicitação síncrona geralmente atingir o tempo limite. Nesse caso, você pode decidir usar o tópico de resposta, mas ainda fazer sua solicitação de forma síncrona.
- Você já está usando um agente de mensagens para a maior parte de sua comunicação e deseja usar a imposição de esquema existente e a compatibilidade com versões anteriores que são automaticamente suportadas pelas ferramentas usadas com o Kafka.
Uma das desvantagens desse padrão é que você não obtém uma resposta imediata sobre se a solicitação foi bem-sucedida ou, pelo menos, recebida com êxito. Muitas vezes, em uma situação de “fazer alguma ação”, essa informação é realmente útil para saber imediatamente, especialmente se estiver em algum tipo de transação lógica.
Se você usar esse padrão, provavelmente alterará o padrão normal da arquitetura Kafka e terá vários produtores com um único consumidor . Neste caso, o consumidor possui o esquema, não o produtor, que é uma forma não óbvia de trabalhar.
Unindo e aprimorando tópicos
Um caso de uso comum para microsserviços é unir dois tópicos ou aprimorar um tópico existente com informações adicionais. Na Flipp , por exemplo, podemos ter um tópico que contém informações do produto e outro tópico que adiciona uma categoria ao produto com base em alguma entrada.
Existem ferramentas existentes que ajudam nesses casos de uso, como Kafka Streams . Estes têm seus usos, mas há muitas armadilhas envolvidas em usá-los:
- Seus tópicos devem ter o mesmo esquema de chave. Qualquer alteração no esquema de chave pode exigir um novo particionamento, o que pode ser caro.
- Seus tópicos devem ter aproximadamente a mesma taxa de transferência — se um dos tópicos tiver muito mais ou muito mais mensagens do que o outro, você ficará preso ao pior dos dois tópicos. Você pode acabar juntando um tópico “pequeno e rápido” (muitas atualizações, mensagens pequenas) com um tópico “grande, lento” (menos atualizações, mensagens maiores) e ter que gerar um tópico “grande e rápido”, que pode destruir seus serviços a jusante.
- Você está basicamente dobrando seu uso de dados toda vez que transforma um tópico em outro. Embora você obtenha as vantagens de um serviço menos stateful, você paga o preço em carga em seus corretores e mais um elo em uma corrente que pode ser quebrada.
- As partes internas desses serviços podem ser opacas e difíceis de entender. Por exemplo, por padrão, eles usam o próprio Kafka como seu estado interno, resultando em mais pressão sobre o agente de mensagens e muitos tópicos temporários.
Na Flipp, começamos a deixar de usar o Kafka Streams e preferimos usar gravações parciais em armazenamentos de dados. Se os tópicos precisam ser unidos, usamos uma ferramenta como o Deimos para facilitar o despejo de tudo em um banco de dados local e produzi-los novamente usando qualquer esquema e cadência que faça sentido.
Conclusão
Os agentes e tópicos de mensagens são uma maneira rica de aumentar sua arquitetura, reduzir dependências e aumentar a segurança e a escalabilidade. Projetar seus sistemas e tópicos não é uma tarefa trivial, e apresentei alguns padrões que achei úteis. Como todo o resto, eles não devem ser usados em todas as situações, mas há muitos casos em que usá-los resultará em uma arquitetura mais robusta, com desempenho e manutenção.



