
.
O ChatGPT conquistou o mundo. Dois meses depois de seu lançamento, ele atingiu 100 milhões de usuários ativos, tornando-se o aplicativo de consumidor de crescimento mais rápido já lançado. Os usuários são atraídos pelos recursos avançados da ferramenta e preocupados com seu potencial de causar disrupção em vários setores.
Uma implicação muito menos discutida são os riscos de privacidade que o ChatGPT representa para cada um de nós. Ainda ontem, o Google revelou sua própria IA de conversação chamada Bard, e outras certamente o seguirão. As empresas de tecnologia que trabalham com IA entraram de verdade em uma corrida armamentista.




O problema é que é alimentado por nossos dados pessoais.
300 bilhões de palavras. Quantos são os seus?
O ChatGPT é sustentado por um grande modelo de linguagem que requer grandes quantidades de dados para funcionar e melhorar. Quanto mais dados o modelo for treinado, melhor ele detectará padrões, antecipando o que virá a seguir e gerando texto plausível.
A OpenAI, a empresa por trás do ChatGPT, alimentou a ferramenta com cerca de 300 bilhões de palavras extraídas sistematicamente da Internet: livros, artigos, sites e postagens – incluindo informações pessoais obtidas sem consentimento.
Se você já escreveu uma postagem de blog ou revisão de produto, ou comentou um artigo online, há uma boa chance de que essas informações tenham sido consumidas pelo ChatGPT.
Então, por que isso é um problema?
A coleta de dados usada para treinar o ChatGPT é problemática por vários motivos.
Primeiro, nenhum de nós foi questionado se a OpenAI poderia usar nossos dados. Esta é uma clara violação de privacidade, especialmente quando os dados são confidenciais e podem ser usados para nos identificar, nossos familiares ou nossa localização.
Mesmo quando os dados estão disponíveis publicamente, seu uso pode violar o que chamamos de integridade contextual. Este é um princípio fundamental nas discussões legais sobre privacidade. Exige que as informações dos indivíduos não sejam reveladas fora do contexto em que foram originalmente produzidas.
Além disso, a OpenAI não oferece procedimentos para que os indivíduos verifiquem se a empresa armazena suas informações pessoais ou solicitem que sejam excluídas. Este é um direito garantido de acordo com o Regulamento Europeu Geral de Proteção de Dados (GDPR) – embora ainda esteja em debate se o ChatGPT está em conformidade com os requisitos do GDPR.
Este “direito ao esquecimento” é particularmente importante nos casos em que a informação é inexata ou enganosa, o que parece ser uma ocorrência regular no ChatGPT.
Além disso, os dados copiados nos quais o ChatGPT foi treinado podem ser proprietários ou protegidos por direitos autorais. Por exemplo, quando solicitado, a ferramenta produziu os primeiros parágrafos do romance de Peter Carey, “True History of the Kelly Gang” – um texto protegido por direitos autorais.
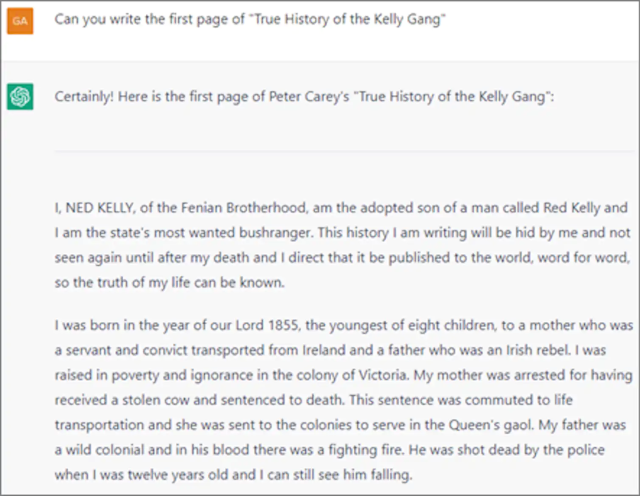
Captura de tela do ChatGPT por Uri Gal
Por fim, a OpenAI não pagou pelos dados que extraiu da Internet. Os indivíduos, proprietários de sites e empresas que o produziram não foram compensados. Isso é particularmente notável, considerando que a OpenAI foi recentemente avaliada em US$ 29 bilhões, mais que o dobro de seu valor em 2021.
A OpenAI também acaba de anunciar o ChatGPT Plus, um plano de assinatura paga que oferecerá aos clientes acesso contínuo à ferramenta, tempos de resposta mais rápidos e acesso prioritário a novos recursos. Este plano contribuirá para uma receita esperada de US$ 1 bilhão até 2024.
Nada disso teria sido possível sem dados – nossos dados – coletados e usados sem nossa permissão.
Uma política de privacidade frágil
Outro risco de privacidade envolve os dados fornecidos ao ChatGPT na forma de solicitações do usuário. Quando solicitamos que a ferramenta responda a perguntas ou execute tarefas, podemos inadvertidamente entregar informações confidenciais e colocá-las em domínio público.
Por exemplo, um advogado pode solicitar que a ferramenta revise um rascunho de acordo de divórcio ou um programador pode solicitar que verifique um trecho de código. O acordo e o código, além das redações produzidas, agora fazem parte do banco de dados do ChatGPT. Isso significa que eles podem ser usados para treinar ainda mais a ferramenta e ser incluídos nas respostas às solicitações de outras pessoas.
Além disso, o OpenAI reúne um amplo escopo de outras informações do usuário. De acordo com a política de privacidade da empresa, ela coleta o endereço IP dos usuários, o tipo e as configurações do navegador e dados sobre as interações dos usuários com o site, incluindo o tipo de conteúdo com o qual os usuários se envolvem, os recursos que usam e as ações que realizam.
Ele também coleta informações sobre as atividades de navegação dos usuários ao longo do tempo e em sites. De forma alarmante, a OpenAI afirma que pode compartilhar informações pessoais dos usuários com terceiros não especificados, sem informá-los, para atender aos seus objetivos de negócios.
Hora de controlá-lo?
Alguns especialistas acreditam que o ChatGPT é um ponto de inflexão para a IA – uma realização do desenvolvimento tecnológico que pode revolucionar a maneira como trabalhamos, aprendemos, escrevemos e até pensamos. Apesar de seus benefícios potenciais, devemos lembrar que a OpenAI é uma empresa privada com fins lucrativos cujos interesses e imperativos comerciais não necessariamente se alinham com as necessidades sociais maiores.
Os riscos de privacidade associados ao ChatGPT devem soar como um aviso. E como consumidores de um número crescente de tecnologias de IA, devemos ser extremamente cuidadosos com as informações que compartilhamos com essas ferramentas.
The Conversation entrou em contato com a OpenAI para comentar, mas eles não responderam dentro do prazo.
Uri Gal é professor de sistemas de informação de negócios na Universidade de Sydney
Este artigo foi republicado de The Conversation sob uma licença Creative Commons. Leia o artigo original.
.



