

.
xINSTALE CLICANDO NO ARQUIVO PARA DOWNLOAD


XDefiant, um jogo de tiro em primeira pessoa lançado recentemente pela Ubisoft, apresenta uma variedade de facções e classes, cada uma com suas habilidades e armas únicas. No entanto, como qualquer jogo, o XDefiant é suscetível a erros e bugs que podem arruinar a experiência de jogo.
Um desses erros que os jogadores encontram é o código de erro DELTA-08, que pode resultar de problemas no servidor, problemas de conectividade de rede ou mau funcionamento do hardware.
Neste artigo, abordaremos as várias causas do erro DELTA-08 e ofereceremos soluções eficazes para resolvê-lo.
O que é o código de erro Xdefiant Delta-08?
O código de erro DELTA-08 geralmente ocorre quando o jogo não consegue se conectar ao servidor ou quando há um problema com a conexão de rede do jogador.
Existem vários motivos pelos quais o código de erro Xdefiant Error Code DELTA-08 pode ocorrer. Algumas das razões comuns incluem:
- Problemas do servidor: Se os servidores XDefiant estiverem inativos ou com problemas, os jogadores podem não conseguir se conectar ao jogo, resultando no erro DELTA-08.
- Problemas de conexão de rede: Se sua conexão com a internet estiver instável, desconectada ou lenta, talvez você não consiga se conectar aos servidores XDefiant.
- Restrições de firewall: Alguns firewalls ou software antivírus podem restringir o acesso aos servidores XDefiant, causando o erro DELTA-08.
- Avarias de hardware: Mau funcionamento, como adaptadores de rede ou roteadores com defeito, pode causar esse erro.
Como corrigir o código de erro Xdefiant Delta-08?
Antes de entrar nas soluções listadas abaixo:
- Verifique os servidores XDefiant. Se o servidor estiver inativo, você precisará aguardar até que os servidores voltem a ficar online. Você pode monitorar o status do servidor visitando o site de suporte da Ubisoft.
- Além disso, verifique a conectividade de rede, pois pode ser necessário solucionar problemas de conectividade de rede se sua conexão com a Internet estiver instável, lenta ou desconectada.
- Verifique seu adaptador de rede, roteador ou outros dispositivos de hardware e reinicie-os.
Se você ainda estiver enfrentando o código de erro Xdefiant Delta-08, tente as seguintes etapas.
Índice:
- Atualizar driver de rede
- Atualize o jogo
- Limpar cache do jogo
- Desativar aplicativos em segundo plano
1. Atualize o driver de rede
Tempo necessário: 4 minutos.
- Abra a caixa Executar: Pressione a tecla Windows + R para abrir a caixa Executar.
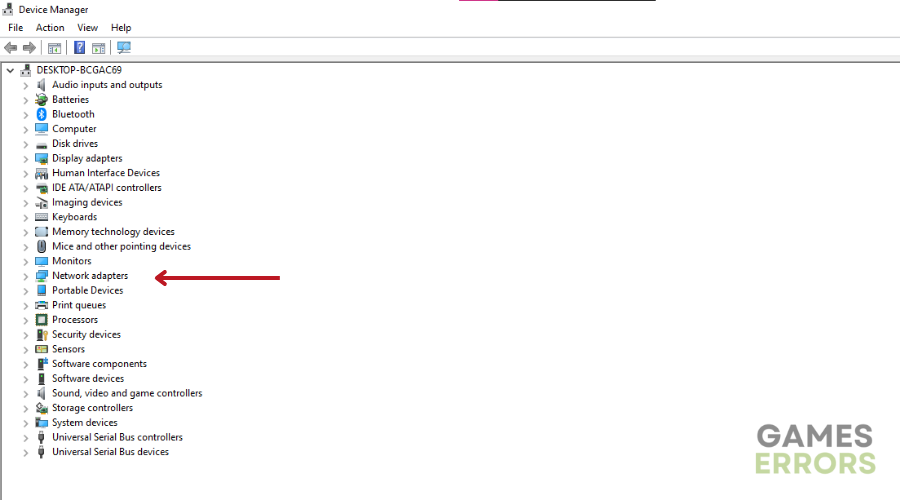
- Abra o Gerenciador de Dispositivos: Digite “devmgmt.msc” na caixa Executar e clique em OK para abrir o Gerenciador de Dispositivos.

- Localize os adaptadores de rede: Clique duas vezes em Adaptadores de rede para visualizar a lista de drivers de rede em seu PC.
- Atualizar driver de rede: clique com o botão direito do mouse no driver de rede dedicado que você está usando e escolha Atualizar driver.
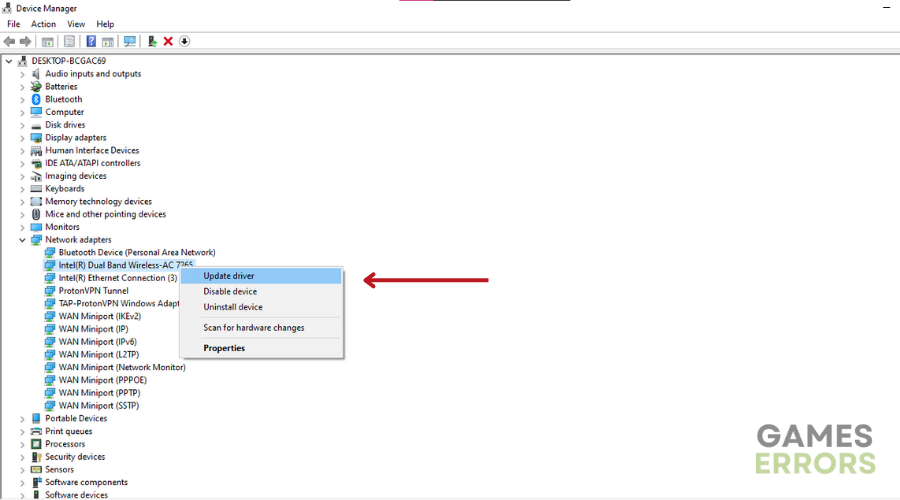
- Instalar Driver: Selecione “Pesquisar drivers automaticamente” e deixe o Windows encontrar e atualizar os drivers.
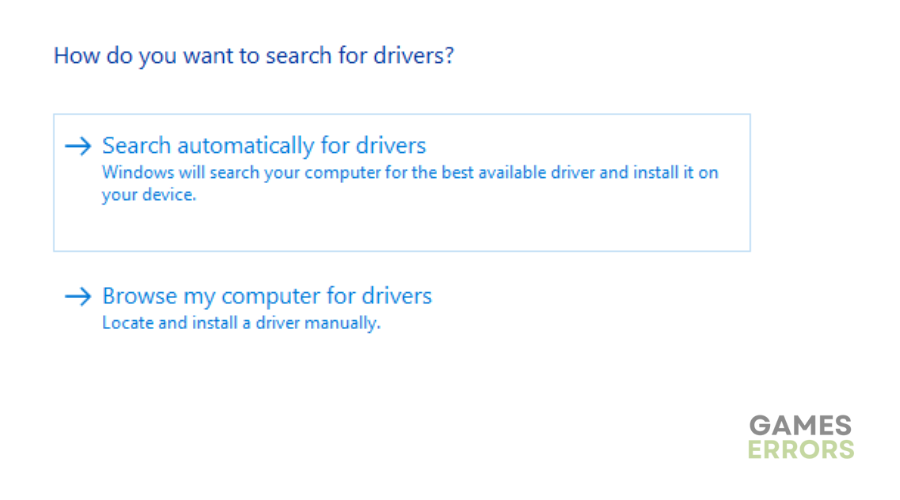
- Inicie o Xdefiant para ver se o problema foi resolvido.
Se você não achar o gerenciador de dispositivos tão confiável quanto deveria, recomendamos usar Atualizador de Driver Outbyte. O Outbyte Driver Updater elimina toda a dor do processo, automatizando a pesquisa e a atualização de seus drivers. Ele verifica seu computador para identificar dispositivos e drivers atualmente instalados e recomenda atualizações apenas de fontes oficiais.
⇒ Obtenha o atualizador de driver Outbyte
2. Atualize o jogo
Ao iniciar um jogo, recomendamos verificar se há atualizações e instalá-lo na versão mais recente.
📝 Etapas para atualizar o jogo XDefiant no Xbox:
- Ligue o console Xbox e entre na sua conta.
- Navegue até o “Meus jogos e aplicativos” seção na tela inicial.
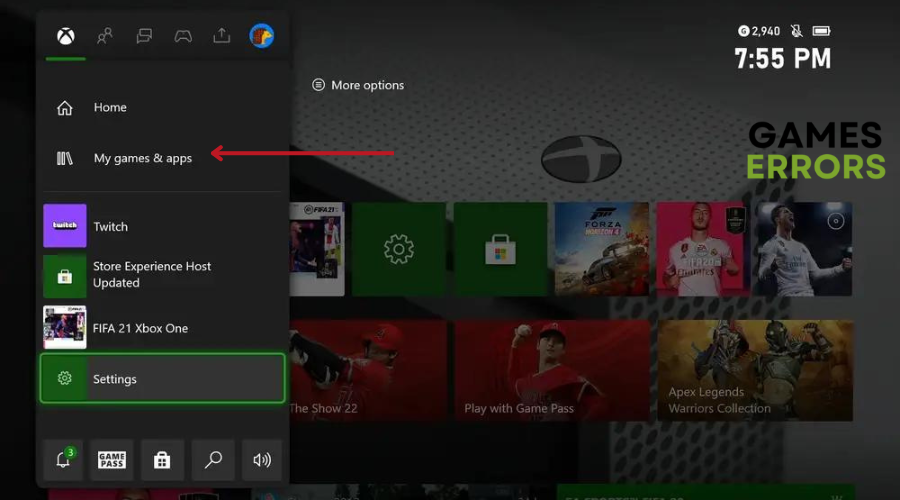
- Localize e selecione “XDefiant” na lista de jogos instalados.
- aperte o “Cardápio” botão (as três linhas horizontais) no seu controlador para abrir o menu de opções.
- Escolher “Gerenciar jogos e complementos” das opções.
- Se uma atualização estiver disponível, você a verá listada em “Atualizações.”
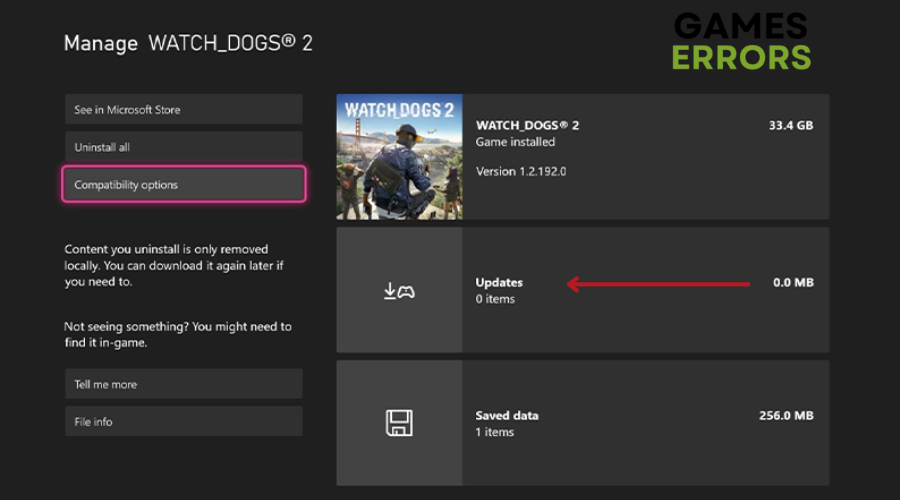
- Selecione a atualização e escolha “Atualizar tudo” ou “Atualizar selecionado” para iniciar o processo de atualização.
- Aguarde a atualização baixar e instalar.
- Quando a atualização estiver concluída, inicie o XDefiant e comece a jogar a versão atualizada.
📝 Etapas para atualizar o XDefiant:
- Destaque o ícone do jogo XDefiant no menu inicial.
- aperte o Botão de opções para exibir o menu de opções.
- Selecione “Verifique atualizações.”
- Se uma atualização estiver disponível, siga as instruções para instalar a atualização
3. Limpe o cache do jogo
- Feche completamente o Ubisoft Connect no seu PC.
- Vá para o local de instalação do Ubisoft Connect PC.
- Os arquivos de instalação podem ser encontrados em: C:Arquivos de Programas (x86)UbisoftUbisoft Game Launcher.
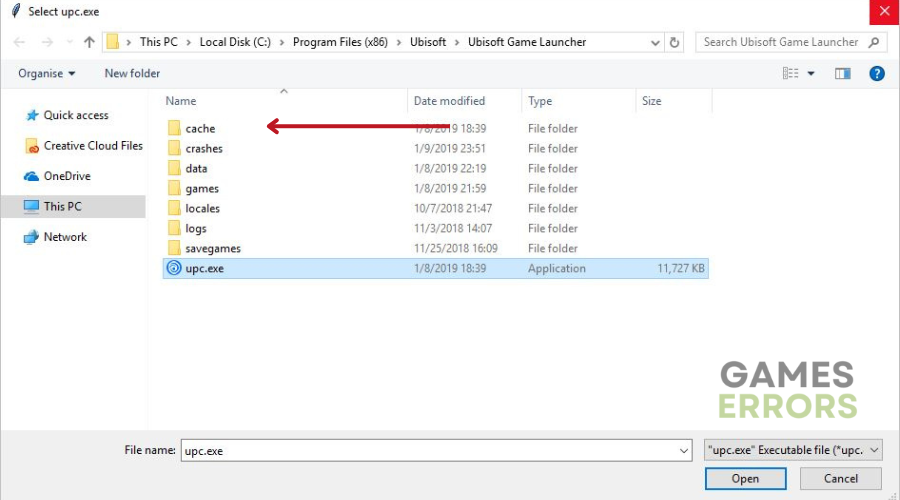
- Clique com o botão direito do mouse na pasta de cache e renomeie-a para outra coisa, como “cache_backup”.
- Reinicie o Ubisoft Connect PC.
- Uma pasta de cache nova e vazia será criada automaticamente.
4. Desative aplicativos em segundo plano
- Imprensa Ctrl + Shift + Esc para abrir o Gerenciador de Tarefas.
- Vou ao “Processos” ou “Detalhes” aba.

- Procure aplicativos ou processos desnecessários em execução em segundo plano que você deseja desativar.
- Clique com o botão direito do mouse no aplicativo/processo e selecione “Finalizar tarefa”.
Artigos relacionados:
Conclusão
Ao longo deste artigo, exploramos as várias causas do código de erro DELTA-08 e fornecemos soluções eficazes para resolvê-lo. É essencial primeiro verificar o status dos servidores XDefiant e solucionar problemas de conectividade de rede. Além disso, reiniciar adaptadores de rede, roteadores e outros dispositivos de hardware pode ajudar a resolver qualquer mau funcionamento de hardware subjacente. Feliz jogo!
Se você encontrar algum problema ou erro ao jogar seus jogos favoritos e precisar de suporte, sinta-se à vontade para entrar em contato conosco aqui. Nossa equipe está sempre pronta para ajudá-lo e garantir que sua experiência de jogo seja perfeita e agradável.
.



