

.

A compactação eficaz consiste em encontrar padrões para diminuir os dados sem perder informações. Quando um algoritmo ou modelo consegue adivinhar com precisão o próximo dado em uma sequência, isso mostra que é bom em detectar esses padrões. Isso vincula a ideia de fazer boas suposições – que é o que grandes modelos de linguagem como o GPT-4 fazem muito bem – a obter uma boa compactação.
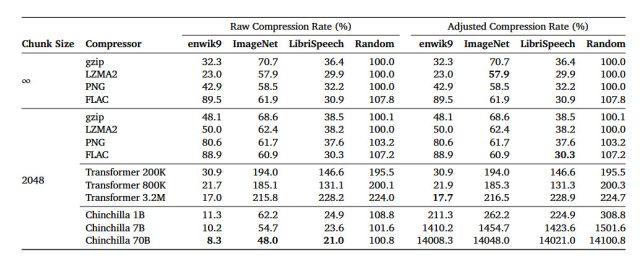
Em um artigo de pesquisa arXiv intitulado “Modelagem de linguagem é compressão”, os pesquisadores detalham sua descoberta de que o modelo de linguagem grande (LLM) DeepMind chamado Chinchilla 70B pode realizar compactação sem perdas em patches de imagem do banco de dados de imagens ImageNet para 43,4 por cento de seu tamanho original, superando o algoritmo PNG, que comprimiu os mesmos dados para 58,5 por cento. Para áudio, o Chinchilla comprimiu amostras dos dados de áudio do LibriSpeech em apenas 16,4% de seu tamanho bruto, superando a compactação FLAC em 30,3%.




Nesse caso, números mais baixos nos resultados significam que está ocorrendo mais compactação. E a compactação sem perdas significa que nenhum dado é perdido durante o processo de compactação. Isso contrasta com uma técnica de compactação com perdas como o JPEG, que elimina alguns dados e reconstrói alguns dos dados com aproximações durante o processo de decodificação para reduzir significativamente o tamanho dos arquivos.
Os resultados do estudo sugerem que, embora o Chinchilla 70B tenha sido treinado principalmente para lidar com texto, ele também é surpreendentemente eficaz na compactação de outros tipos de dados, muitas vezes melhor do que algoritmos projetados especificamente para essas tarefas. Isso abre a porta para pensar em modelos de aprendizado de máquina não apenas como ferramentas para previsão e escrita de texto, mas também como formas eficazes de reduzir o tamanho de vários tipos de dados.
DeepMind
Nas últimas duas décadas, alguns cientistas da computação propuseram que a capacidade de compactar dados de forma eficaz é semelhante a uma forma de inteligência geral. A ideia está enraizada na noção de que compreender o mundo muitas vezes envolve identificar padrões e dar sentido à complexidade, o que, como mencionado acima, é semelhante ao que uma boa compressão de dados faz. Ao reduzir um grande conjunto de dados a um formato menor e mais gerenciável, mantendo suas características essenciais, um algoritmo de compressão demonstra uma forma de compreensão ou representação desses dados, argumentam os proponentes.
O Prêmio Hutter é um exemplo que coloca em foco essa ideia de compressão como uma forma de inteligência. Nomeado em homenagem a Marcus Hutter, pesquisador na área de IA e um dos autores nomeados do artigo DeepMind, o prêmio é concedido a qualquer pessoa que consiga compactar de forma mais eficaz um conjunto fixo de texto em inglês. A premissa subjacente é que uma compressão de texto altamente eficiente exigiria a compreensão dos padrões semânticos e sintáticos da linguagem, semelhante à forma como um ser humano a entende.
Então, teoricamente, se uma máquina consegue comprimir estes dados extremamente bem, isso pode indicar uma forma de inteligência geral – ou pelo menos um passo nessa direção. Embora nem todos na área concordem que ganhar o Prémio Hutter indicaria inteligência geral, o concurso destaca a sobreposição entre os desafios da compressão de dados e os objectivos de criação de sistemas mais inteligentes.
Nesse sentido, os pesquisadores da DeepMind afirmam que a relação entre previsão e compressão não é uma via de mão única. Eles postulam que se você tiver um bom algoritmo de compactação como o gzip, poderá invertê-lo e usá-lo para gerar dados novos e originais com base no que aprendeu durante o processo de compactação.
Em uma seção do artigo (Seção 3.4), os pesquisadores realizaram um experimento para gerar novos dados em diferentes formatos – texto, imagem e áudio – fazendo com que o gzip e o Chinchilla previssem o que vem a seguir em uma sequência de dados após o condicionamento em uma amostra. Compreensivelmente, o gzip não se saiu muito bem, produzindo resultados completamente absurdos – pelo menos para a mente humana. Isso demonstra que, embora o gzip possa ser obrigado a gerar dados, esses dados podem não ser muito úteis a não ser como uma curiosidade experimental. Por outro lado, o Chinchila, que foi concebido tendo em mente o processamento da linguagem, teve um desempenho previsivelmente muito melhor na tarefa generativa.

DeepMind
Embora o artigo da DeepMind sobre compactação de modelos de linguagem de IA não tenha sido revisado por pares, ele fornece uma janela intrigante para possíveis novas aplicações para modelos de linguagem grandes. A relação entre compressão e inteligência é uma questão de debate e pesquisa contínuos, então provavelmente veremos mais artigos sobre o assunto surgirem em breve.
.



