

.

Strong The One
Na segunda-feira, pesquisadores da Microsoft apresentaram o Kosmos-1, um modelo multimodal que pode analisar imagens em busca de conteúdo, resolver quebra-cabeças visuais, realizar reconhecimento visual de texto, passar em testes de QI visual e entender instruções de linguagem natural. Os pesquisadores acreditam que a IA multimodal – que integra diferentes modos de entrada, como texto, áudio, imagens e vídeo – é um passo fundamental para a construção de inteligência geral artificial (AGI) que pode executar tarefas gerais no nível humano.




“Sendo uma parte básica da inteligência, multimodal percepção é uma necessidade para alcançar inteligência geralem termos de aquisição de conhecimento e aterramento para o mundo real”, escrevem os pesquisadores em seu trabalho acadêmico, “A linguagem não é tudo que você precisa: alinhando a percepção com os modelos de linguagem”.
Exemplos visuais do artigo Kosmos-1 mostram o modelo analisando imagens e respondendo a perguntas sobre elas, lendo o texto de uma imagem, escrevendo legendas para imagens e fazendo um teste de QI visual com precisão de 22 a 26 por cento (mais sobre isso abaixo).
-
Um exemplo fornecido pela Microsoft do Kosmos-1 respondendo a perguntas sobre imagens e sites.
Microsoft
-
Um exemplo fornecido pela Microsoft de “inserção de cadeia de pensamento multimodal” para Kosmos-1.
Microsoft
-
Um exemplo do Kosmos-1 respondendo a perguntas visuais, fornecido pela Microsoft.
Microsoft
Enquanto a mídia fala sobre modelos de linguagem grande (LLM), alguns especialistas em IA apontam para a IA multimodal como um caminho potencial para a inteligência artificial geral, uma tecnologia hipotética que será ostensivamente capaz de substituir humanos em qualquer tarefa intelectual (e qualquer trabalho intelectual). . AGI é o objetivo declarado da OpenAI, um importante parceiro de negócios da Microsoft no espaço de IA.
Nesse caso, o Kosmos-1 parece ser um projeto puro da Microsoft sem o envolvimento da OpenAI. Os pesquisadores chamam sua criação de “modelo de linguagem grande multimodal” (MLLM) porque suas raízes estão no processamento de linguagem natural como um LLM somente de texto, como o ChatGPT. E mostra: para Kosmos-1 aceitar entrada de imagem, os pesquisadores devem primeiro traduzir a imagem em uma série especial de tokens (basicamente texto) que o LLM possa entender. O artigo Kosmos-1 descreve isso com mais detalhes:
Para o formato de entrada, achatamos a entrada como uma sequência decorada com tokens especiais. Especificamente, usamos
e para denotar o início e o fim da sequência. Os tokens especiaise indicam o início e o fim das incorporações de imagens codificadas. Por exemplo, “documento ” é uma entrada de texto e “parágrafo” é uma entrada de texto de imagem intercalada.Incorporação de imagem parágrafo… Um módulo de incorporação é usado para codificar tokens de texto e outras modalidades de entrada em vetores. Em seguida, as incorporações são alimentadas no decodificador. Para tokens de entrada, usamos uma tabela de pesquisa para mapeá-los em incorporações. Para as modalidades de sinais contínuos (por exemplo, imagem e áudio), também é possível representar entradas como código discreto e então considerá-las como “línguas estrangeiras”.
A Microsoft treinou o Kosmos-1 usando dados da web, incluindo trechos de The Pile (um recurso de texto em inglês de 800 GB) e Common Crawl. Após o treinamento, eles avaliaram as habilidades do Kosmos-1 em vários testes, incluindo compreensão de linguagem, geração de linguagem, classificação de texto livre de reconhecimento óptico de caracteres, legenda de imagem, resposta visual a perguntas, resposta a perguntas de páginas da web e classificação de imagem zero-shot. Em muitos desses testes, o Kosmos-1 superou os modelos atuais de última geração, de acordo com a Microsoft.
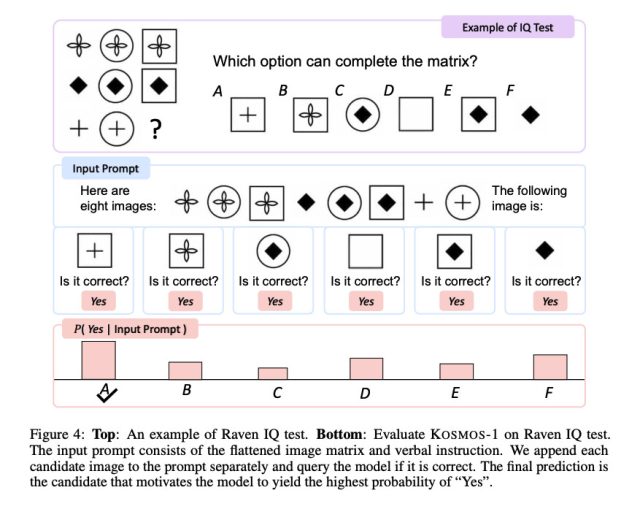
Microsoft
De particular interesse é o desempenho do Kosmos-1 no Raciocínio Progressivo de Raven, que mede o QI visual apresentando uma sequência de formas e pedindo ao candidato para completar a sequência. Para testar o Kosmos-1, os pesquisadores preencheram um teste, um de cada vez, com cada opção preenchida e perguntaram se a resposta estava correta. O Kosmos-1 só conseguiu responder corretamente a uma pergunta no teste Raven 22% das vezes (26% com ajuste fino). Isso não é de forma alguma um slam dunk, e erros na metodologia podem ter afetado os resultados, mas o Kosmos-1 superou a chance aleatória (17%) no teste de QI Raven.
Ainda assim, embora o Kosmos-1 represente os primeiros passos no domínio multimodal (uma abordagem também perseguida por outros), é fácil imaginar que otimizações futuras possam trazer resultados ainda mais significativos, permitindo que modelos de IA percebam qualquer forma de mídia e atuem sobre ela , o que aumentará muito as habilidades dos assistentes artificiais. No futuro, os pesquisadores dizem que gostariam de aumentar o Kosmos-1 em tamanho de modelo e também integrar a capacidade de fala.
A Microsoft diz que planeja disponibilizar o Kosmos-1 para os desenvolvedores, embora a página do GitHub que o jornal cita não tenha nenhum código específico específico do Kosmos após a publicação desta história.
.



