

.

Na sexta-feira, pesquisadores da Nvidia, UPenn, Caltech e da Universidade do Texas em Austin anunciaram Eureka, um algoritmo que usa o modelo de linguagem GPT-4 da OpenAI para projetar objetivos de treinamento (chamados de “funções de recompensa”) para melhorar a destreza do robô. O trabalho visa preencher a lacuna entre o raciocínio de alto nível e o controle motor de baixo nível, permitindo que os robôs aprendam tarefas complexas rapidamente usando simulações massivamente paralelas que executam testes simultaneamente. De acordo com a equipe, Eureka supera as funções de recompensa escritas por humanos por uma margem substancial.
Antes que os robôs possam interagir com sucesso com o mundo real, eles precisam aprender como mover seus corpos robóticos para atingir objetivos – como pegar objetos ou se mover. Em vez de fazer um robô físico tentar e falhar uma tarefa de cada vez para aprender em um laboratório, os pesquisadores da Nvidia têm experimentado o uso de mundos de computador semelhantes a videogames (graças às plataformas chamadas Isaac Sim e Isaac Gym) que simulam tridimensionais. física. Isso permite que sessões de treinamento massivamente paralelas ocorram em muitos mundos virtuais ao mesmo tempo, acelerando drasticamente o tempo de treinamento.



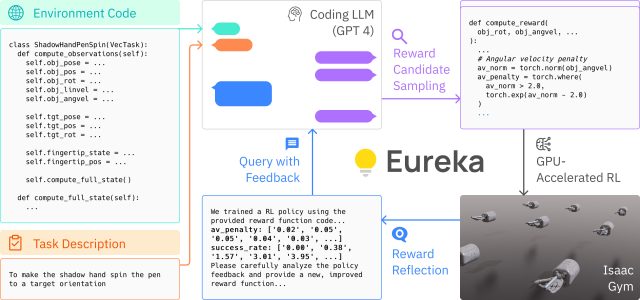
“Aproveitando a simulação acelerada por GPU de última geração no Nvidia Isaac Gym”, escreve a Nvidia em sua página de demonstração, “Eureka é capaz de avaliar rapidamente a qualidade de um grande lote de candidatos a recompensa, permitindo pesquisa escalonável na função de recompensa espaço.” Eles chamam isso de “avaliação rápida de recompensa por meio de aprendizado de reforço massivamente paralelo”.
Os pesquisadores descrevem o Eureka como uma “arquitetura gradiente híbrida”, o que essencialmente significa que é uma mistura de dois modelos de aprendizagem diferentes. Uma rede neural de baixo nível dedicada ao controle motor do robô recebe instruções de um modelo de linguagem grande (LLM) de alto nível somente para inferência, como o GPT-4. A arquitetura emprega dois loops: um loop externo usando GPT-4 para refinar a função de recompensa e um loop interno para aprendizado por reforço para treinar o sistema de controle do robô.
A pesquisa é detalhada em um novo artigo de pesquisa pré-impresso intitulado “Eureka: Human-Level Reward Design via Coding Large Language Models”. Os autores Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi “Jim” Fan e Anima Anandkumar usaram o já mencionado Isaac Gym, um simulador de física acelerado por GPU, para supostamente acelerar o processo de treinamento físico por um fator de 1.000. No resumo do artigo, os autores afirmam que Eureka superou as recompensas de engenharia humana especializada em 83% de um conjunto de benchmark de 29 tarefas em 10 robôs diferentes, melhorando o desempenho em uma média de 52%.
Além disso, Eureka introduz uma nova forma de aprendizagem por reforço a partir de feedback humano (RLHF), permitindo que o feedback da linguagem natural de um operador humano influencie a função de recompensa. Isso poderia servir como um “co-piloto poderoso” para engenheiros que projetam comportamentos motores sofisticados para robôs, de acordo com um post X do pesquisador de IA da Nvidia, Fan, que é autor listado no artigo de pesquisa Eureka. Uma conquista surpreendente, diz Fan, é que Eureka permitiu que robôs realizassem truques de girar canetas, uma habilidade que é difícil de animar até mesmo para artistas de CGI.
Então o que tudo isso significa? No futuro, ensinar novos truques aos robôs provavelmente ocorrerá em velocidade acelerada graças a simulações massivamente paralelas, com uma pequena ajuda de modelos de IA que podem supervisionar o processo de treinamento. O trabalho mais recente é adjacente a experimentos anteriores usando modelos de linguagem para controlar robôs da Microsoft e do Google.
No X, Shital Shah, principal engenheiro de pesquisa da Microsoft Research, escreveu que a abordagem Eureka parece ser um passo fundamental para a realização de todo o potencial da aprendizagem por reforço: “O proverbial ciclo de feedback positivo de autoaperfeiçoamento pode estar ao virar da esquina, o que nos permite ir além dos dados e capacidades do treinamento humano.”
A equipe Eureka disponibilizou publicamente sua pesquisa e base de código para futuras experimentações e para futuros pesquisadores desenvolverem. O artigo pode ser acessado no arXiv e o código está disponível no GitHub.
.


