

.

Imagine digitar “música de introdução dramática” e ouvir uma sinfonia crescente ou escrever “passos assustadores” e obter efeitos sonoros de alta qualidade. Essa é a promessa do Stable Audio, um modelo de IA de texto para áudio anunciado na quarta-feira pela Stability AI que pode sintetizar música ou sons a partir de descrições escritas. Em pouco tempo, uma tecnologia semelhante poderá desafiar os músicos no seu trabalho.
Se você se lembra, Stability AI é a empresa que ajudou a financiar a criação de Stable Diffusion, um modelo de síntese de imagem de difusão latente lançado em agosto de 2022. Não contente em se limitar à geração de imagens, a empresa ramificou-se para áudio apoiando Harmonai, um laboratório de IA que lançou o gerador de música Dance Diffusion em setembro.




Agora, Stability e Harmonai querem entrar na produção comercial de áudio de IA com Stable Audio. A julgar pelas amostras de produção, parece uma atualização significativa na qualidade de áudio em relação aos geradores de áudio de IA anteriores que vimos.
Em sua página promocional, Stability fornece exemplos do modelo de IA em ação com avisos como “música de trailer épica, percussão tribal intensa e metais” e “lofi hip hop beat melodic chillhop 85 bpm”. Ele também oferece amostras de efeitos sonoros gerados usando áudio estável, como um piloto de avião falando por um interfone e pessoas conversando em um restaurante movimentado.
Para treinar seu modelo, a Stability fez parceria com o provedor de música AudioSparx e licenciou um conjunto de dados “consistindo em mais de 800.000 arquivos de áudio contendo música, efeitos sonoros e hastes de um único instrumento, bem como metadados de texto correspondentes”. Depois de alimentar o modelo com 19.500 horas de áudio, o Stable Audio sabe como imitar certos sons que ouviu sob comando porque os sons foram associados a descrições de texto deles em sua rede neural.
IA de estabilidade
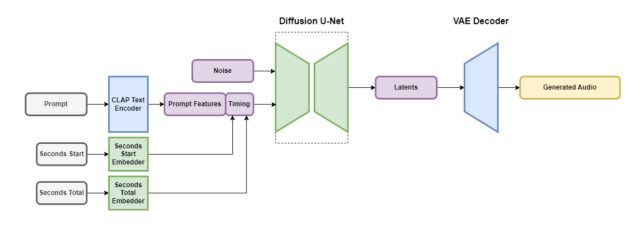
Stable Audio contém várias partes que funcionam juntas para criar áudio personalizado rapidamente. Uma parte reduz o arquivo de áudio de uma forma que mantém seus recursos importantes enquanto remove ruídos desnecessários. Isso torna o sistema mais rápido no ensino e na criação de novo áudio. Outra parte usa texto (descrições de metadados da música e dos sons) para ajudar a orientar o tipo de áudio gerado.
Para acelerar as coisas, a arquitetura Stable Audio opera em uma representação de áudio compactada e altamente simplificada para reduzir o tempo de inferência (a quantidade de tempo que leva para um modelo de aprendizado de máquina gerar uma saída depois de receber uma entrada). De acordo com a Stability AI, o Stable Audio pode renderizar 95 segundos de áudio estéreo a uma taxa de amostragem de 44,1 kHz (geralmente chamada de “qualidade de CD”) em menos de um segundo em uma GPU Nvidia A100. A A100 é uma GPU robusta de data center projetada para uso de IA e é muito mais capaz do que uma GPU típica para jogos de desktop.
Como mencionado, Stable Audio não é o primeiro gerador de música baseado em técnicas de difusão latente. Em dezembro passado, cobrimos Riffusion, uma versão amadora de uma versão em áudio do Stable Diffusion, embora suas gerações resultantes estivessem longe das amostras do Stable Audio em qualidade. Em janeiro, o Google lançou o MusicLM, um gerador de música AI para áudio de 24 kHz, e a Meta lançou um conjunto de ferramentas de áudio de código aberto (incluindo um gerador de texto para música) chamado AudioCraft em agosto. Agora, com áudio estéreo de 44,1 kHz, o Stable Diffusion está aumentando a aposta.
A estabilidade diz que o Stable Audio estará disponível em um nível gratuito e em um plano Pro mensal de US$ 12. Com a opção gratuita, os usuários podem gerar até 20 faixas por mês, cada uma com duração máxima de 20 segundos. O plano Pro expande esses limites, permitindo 500 gerações de faixas por mês e durações de faixa de até 90 segundos. Espera-se que os futuros lançamentos do Stability incluam modelos de código aberto baseados na arquitetura Stable Audio, bem como código de treinamento para aqueles interessados em desenvolver modelos de geração de áudio.
Do jeito que está, parece que podemos estar no limite da música gerada por IA com qualidade de produção com Áudio Estável, considerando sua fidelidade de áudio. Os músicos ficarão felizes se forem substituídos por modelos de IA? Provavelmente não, se a história nos mostrou alguma coisa, desde protestos contra a IA no campo das artes visuais. Por enquanto, um ser humano pode facilmente superar qualquer coisa que a IA possa gerar, mas isso pode não ser o caso por muito tempo. De qualquer forma, o áudio gerado por IA pode se tornar outra ferramenta na caixa de ferramentas de produção de áudio de um profissional.
.



