

.

meio da jornada
Na terça-feira, a Meta anunciou o Llama 2, uma nova família de modelos de linguagem AI de código aberto notável por sua licença comercial, o que significa que os modelos podem ser integrados a produtos comerciais, ao contrário de seu antecessor. Eles variam em tamanho de 7 a 70 bilhões de parâmetros e supostamente “superam os modelos de chat de código aberto na maioria dos benchmarks que testamos”, de acordo com a Meta.




“Isso vai mudar o cenário do mercado LLM”, tuitou Cientista Chefe de IA Yann LeCun. “O Llama-v2 está disponível no Microsoft Azure e estará disponível no AWS, Hugging Face e outros provedores.”
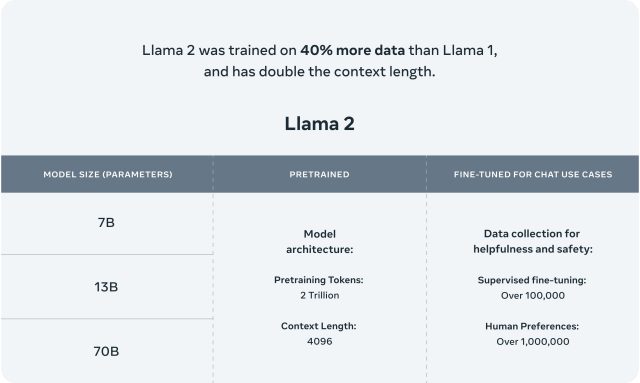
De acordo com a Meta, seus modelos “pré-treinados” do Llama 2 (os modelos básicos) são treinados em 2 trilhões de tokens e têm uma janela de contexto de 4.096 tokens (fragmentos de palavras). A janela de contexto determina o tamanho do conteúdo que o modelo pode processar de uma só vez. A Meta também diz que os modelos ajustados do Llama 2, desenvolvidos para aplicativos de bate-papo semelhantes ao ChatGPT, foram treinados em “mais de 1 milhão de anotações humanas”.
Embora não consiga igualar o desempenho do GPT-4 da OpenAI, o Llama 2 aparentemente se sai bem para um modelo de código aberto. De acordo com Jim Fan, cientista sênior de IA da Nvidia, “o 70B está próximo do GPT-3.5 em tarefas de raciocínio, mas há uma lacuna significativa nos benchmarks de codificação. Está no mesmo nível ou melhor do que o PaLM-540B na maioria dos benchmarks, mas ainda muito atrás do GPT-4 e do PaLM-2-L.” Mais detalhes sobre o desempenho, benchmarks e construção do Llama 2 podem ser encontrados em um trabalho de pesquisa divulgado pela Meta na terça-feira.
meta
Em fevereiro, a Meta lançou o precursor do Llama 2, LLaMA, como código aberto com licença não comercial. Disponível oficialmente apenas para acadêmicos com certas credenciais, alguém logo vazou os pesos do LLaMA (arquivos contendo os valores dos parâmetros das redes neurais treinadas) para sites de torrent, e eles se espalharam amplamente na comunidade de IA. Logo, variações refinadas de LLaMA, como Alpaca, surgiram, fornecendo a semente de uma cena de desenvolvimento de LLM underground em rápido crescimento.
O Llama 2 traz essa atividade mais abertamente com sua permissão para uso comercial, embora os licenciados em potencial com “mais de 700 milhões de usuários ativos mensais no mês anterior” devam solicitar permissão especial da Meta para usá-lo, potencialmente impedindo seu uso gratuito por gigantes do tamanho da Amazon ou do Google.
O poder e o perigo da IA de código aberto
Embora os modelos de IA de código aberto tenham se mostrado populares entre entusiastas e pessoas que buscam chatbots sem censura, eles também se mostraram controversos. Meta é notável por estar sozinho entre os gigantes da tecnologia no suporte aos principais modelos de fundação de código aberto, enquanto aqueles no canto de código fechado incluem OpenAI, Microsoft e Google.
Os críticos dizem que os modelos de IA de código aberto apresentam riscos potenciais, como uso indevido em biologia sintética ou geração de spam ou desinformação. É fácil imaginar o Llama 2 preenchendo algumas dessas funções, embora tais usos violem os termos de serviço da Meta. Atualmente, se alguém realizar atos restritos com a API ChatGPT da OpenAI, o acesso pode ser revogado. Mas com o software de código aberto, uma vez que os pesos são liberados, não há como recuperá-los.
No entanto, os defensores da IA de código aberto costumam argumentar que os modelos de IA de código aberto incentivam a transparência (em termos dos dados de treinamento usados para criá-los), promovem a competição econômica (não limitando a tecnologia a empresas gigantes), incentivam a liberdade de expressão (sem censura) e democratizam o acesso à IA (sem restrições de acesso pago).
Talvez se antecipando às possíveis críticas por seu lançamento de código aberto, a Meta também publicou uma breve “Declaração de suporte para a abordagem aberta da Meta para a IA atual” que diz: “Apoiamos uma abordagem de inovação aberta para IA. A inovação responsável e aberta nos dá uma participação no processo de desenvolvimento de IA, trazendo visibilidade, escrutínio e confiança a essas tecnologias. A abertura dos modelos Llama de hoje permitirá que todos se beneficiem dessa tecnologia”.
Na tarde de terça-feira, a declaração foi assinada por uma lista de executivos e educadores, como Drew Houston (CEO do Dropbox), Matt Bornstein (sócio da Andreessen Horowitz), Julien Chaumond (CTO da Hugging Face), Lex Fridman (cientista de pesquisa do MIT) e Paul Graham (sócio fundador da Y Combinator).
Embora o Llama 2 seja de código aberto, a Meta não divulgou a fonte dos dados de treinamento usados na criação dos modelos do Llama 2, que Mozilla Senior Fellow of Trustworthy AI Abeba Birhane apontou no Twitter. A falta de transparência dos dados de treinamento ainda é um ponto crítico para alguns críticos do LLM porque os dados de treinamento que ensinam a esses LLMs o que eles “sabem” geralmente vêm de uma raspagem não autorizada da Internet com pouca consideração pela privacidade ou impacto comercial. Meta diz que “fez um esforço para remover dados de certos sites conhecidos por conter um grande volume de informações pessoais sobre indivíduos particulares” no trabalho de pesquisa do Llama 2, mas não listou quais são esses sites.
Atualmente, qualquer pessoa pode solicitar acesso para baixar o Llama 2 preenchendo um formulário no site da Meta. A Strong The One enviou uma solicitação de download e recebeu um link para download cerca de uma hora depois, sugerindo que a lista pode ser examinada manualmente.
.



