

.

Na sexta-feira, o Google DeepMind anunciou o Robotic Transformer 2 (RT-2), um modelo de visão-linguagem-ação (VLA) “primeiro de seu tipo” que usa dados extraídos da Internet para permitir um melhor controle robótico por meio de comandos de linguagem simples. . O objetivo final é criar robôs de uso geral que possam navegar em ambientes humanos, semelhantes a robôs fictícios como WALL-E ou C-3PO.



Quando um ser humano quer aprender uma tarefa, geralmente lemos e observamos. De maneira semelhante, o RT-2 utiliza um grande modelo de linguagem (a tecnologia por trás do ChatGPT) que foi treinado em texto e imagens encontrados online. O RT-2 usa essas informações para reconhecer padrões e executar ações, mesmo que o robô não tenha sido especificamente treinado para realizar essas tarefas – um conceito chamado generalização.
Por exemplo, o Google diz que o RT-2 pode permitir que um robô reconheça e jogue fora o lixo sem ter sido especificamente treinado para isso. Ele usa seu entendimento sobre o que é o lixo e como ele costuma ser descartado para orientar suas ações. O RT-2 até vê embalagens de alimentos descartados ou cascas de banana como lixo, apesar da potencial ambiguidade.

Em outro exemplo, o The New York Times relata um engenheiro do Google dando o comando “Pegue o animal extinto” e o robô RT-2 localiza e escolhe um dinossauro de uma seleção de três estatuetas em uma mesa.
Essa capacidade é notável porque os robôs geralmente são treinados a partir de um grande número de pontos de dados adquiridos manualmente, dificultando esse processo devido ao alto tempo e custo de cobertura de todos os cenários possíveis. Simplificando, o mundo real é uma bagunça dinâmica, com mudanças de situações e configurações de objetos. Um robô auxiliar prático precisa ser capaz de se adaptar em tempo real de maneiras que são impossíveis de programar explicitamente, e é aí que entra o RT-2.
Mais do que se vê
Com o RT-2, o Google DeepMind adotou uma estratégia que aproveita os pontos fortes dos modelos transformadores de IA, conhecidos por sua capacidade de generalizar informações. O RT-2 baseia-se em trabalhos anteriores de IA no Google, incluindo o modelo Pathways Language and Image (PaLI-X) e o modelo Pathways Language Incorporado (PaLM-E). Além disso, o RT-2 também foi co-treinado com dados de seu modelo antecessor (RT-1), que foram coletados durante um período de 17 meses em um “ambiente de cozinha de escritório” por 13 robôs.
A arquitetura RT-2 envolve o ajuste fino de um modelo VLM pré-treinado em robótica e dados da web. O modelo resultante processa as imagens da câmera do robô e prevê as ações que o robô deve executar.
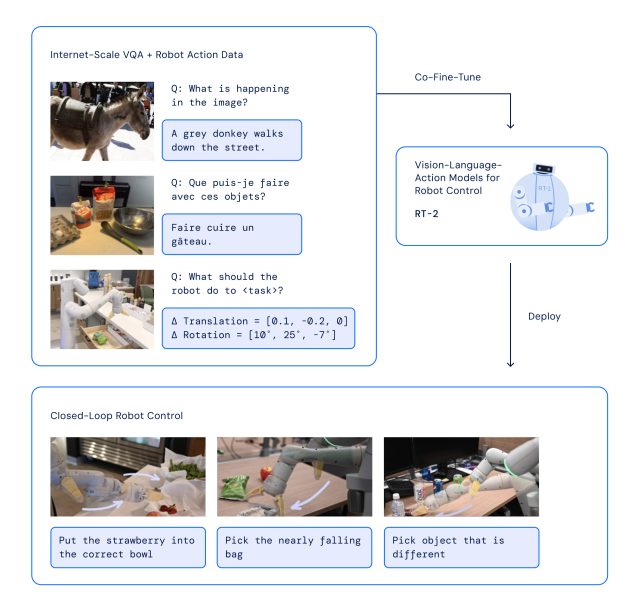
Como o RT-2 usa um modelo de linguagem para processar informações, o Google optou por representar ações como tokens, que são tradicionalmente fragmentos de uma palavra. “Para controlar um robô, ele deve ser treinado para realizar ações”, escreve o Google. “Enfrentamos esse desafio representando ações como tokens na saída do modelo – semelhantes aos tokens de linguagem – e descrevendo ações como strings que podem ser processadas por tokenizadores de linguagem natural padrão”.
No desenvolvimento do RT-2, os pesquisadores usaram o mesmo método de dividir as ações do robô em partes menores, como fizeram com a primeira versão do robô, RT-1. Eles descobriram que, ao transformar essas ações em uma série de símbolos ou códigos (uma representação de “cadeia”), eles poderiam ensinar ao robô novas habilidades usando os mesmos modelos de aprendizado que usam para processar dados da web.
O modelo também utiliza o raciocínio em cadeia de pensamento, permitindo que ele execute um raciocínio em vários estágios, como escolher uma ferramenta alternativa (uma pedra como um martelo improvisado) ou escolher a melhor bebida para uma pessoa cansada (uma bebida energética).

O Google diz que, em mais de 6.000 testes, o RT-2 apresentou desempenho tão bom quanto seu antecessor, o RT-1, em tarefas para as quais foi treinado, chamadas de tarefas “vistas”. No entanto, quando testado com novos cenários “invisíveis”, o RT-2 quase dobrou seu desempenho para 62% em comparação com os 32% do RT-1.
Embora o RT-2 mostre uma grande capacidade de adaptar o que aprendeu a novas situações, o Google reconhece que não é perfeito. Na seção “Limitações” do artigo técnico do RT-2, os pesquisadores admitem que, embora a inclusão de dados da web no material de treinamento “aumente a generalização sobre conceitos semânticos e visuais”, isso não dá magicamente ao robô novas habilidades para realizar movimentos físicos que ele ainda não aprendeu com os dados de treinamento de robôs de seu antecessor. Em outras palavras, ele não pode realizar ações que não praticou fisicamente antes, mas melhora ao usar as ações que já conhece de novas maneiras.
Embora o objetivo final do Google DeepMind seja criar robôs de uso geral, a empresa sabe que ainda há muito trabalho de pesquisa pela frente antes de chegar lá. Mas tecnologias como o RT-2 parecem ser um forte passo nessa direção.
.



